La MA n’est pas juste la réalisation d’une « moyenne simple » de la taille des effets procurés par chaque étude (mesurés par un risque relatif, un odds ratio [OR], un hazard ratio…) pour aboutir à la taille de l’effet commun. En agissant de la sorte, le groupe « intervention » de chaque étude ne disposerait plus de son groupe témoin spécifique. On aboutirait à des résultats paradoxaux, en particulier par le paradoxe de Simpson2 [5,6]. Ainsi, lorsqu’un ou plusieurs des essais inclus dans la MA n’utilisent pas un schéma de randomisation de type « un-pour-un » (i.e. à chaque individu randomisé dans le groupe « intervention » correspond un individu randomisé dans le groupe témoin), la simple mise en commun des données des essais (« moyenne simple ») peut conduire au paradoxe de Simpson.
Dans ce paradoxe (en fait un biais), l’association entre deux variables binaires (par exemple exposition et survenue de maladie) est similaire à l’intérieur de sous-groupes de la population, mais change de signe, si les individus des sous-groupes sont fusionnés et analysés sans stratification. Ceci peut être résumé par le titre de l’article de Baker et Kramer Good for women, good for men, bad for people [7]. Lorsqu’il y a de grandes disparités de taille d’échantillon parmi les essais, l’impact dudit paradoxe peut être assez important. L’exemple du Tableau I illustre un cas de paradoxe de Simpson. Il s’agit d’estimer la relation entre exposition aux lignes électriques à hautes tensions et la survenue de leucémie. Cinq études cas-témoins sont analysées et conduisent à des OR allant dans le même sens, i.e. OR supérieur à 1. En combinant simplement les données de ces cinq études, on aboutit à un OR égal à 0,67, donc inférieur à 1 (en revanche une MA conduit à un OR de 1,28). L’effet commun mesuré par la MA est basé sur une « moyenne pondérée » (stratification). La pondération usuelle est l’inverse de la variance de chaque étude.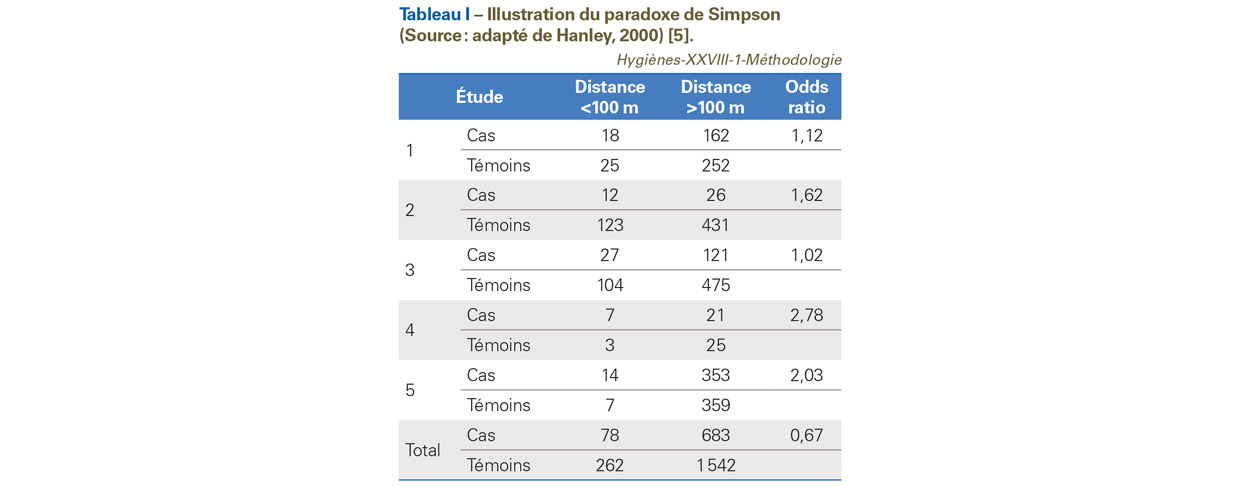
La méta-analyse : une méthode récente
La première MA aurait été effectuée en 1904 par Karl Pearson3 [9] et concerne les maladies infectieuses. L’objectif était d’analyser des données comparant les taux d’infection et mortalité parmi les soldats volontaires, vaccinés contre la fièvre typhoïde, dans divers endroits de l’Empire britannique, à ceux des soldats non vaccinés. Pearson a présenté les résultats de ses analyses dans un tableau dans lequel chaque ligne correspondait à une étude, ligne dans laquelle était notée la mesure de l’effet, ainsi qu’une mesure de l’incertitude. La dernière ligne donnait une estimation globale de l’effet (sans toutefois estimer l’incertitude globale associée à cette estimation). L’une des premières MA relative à un traitement médical curatif est plus tardive, publiée en 1955 par Beecher [10] et le terme « MA », dans son sens statistique, a été proposée par Glass en 1976 [11]. Dans les années 1970, à partir des travaux menés en sciences humaines par Glass [11], Schmidt et Hunter [12], des techniques analytiques plus élaborées apparaissent. D’autres détails historiques figurent dans l’article de O’Rourke [13] et le livre de Hunt et al. [14].
La méta-analyse : une méthode nécessaire
La synthèse quantitative des connaissances scientifiques est nécessaire. Selon Rayleigh, « si comme on le soupçonne parfois, la science n’était rien d’autre que l’accumulation laborieuse de faits, elle s’immobiliserait bientôt écrasée sous son propre poids… Deux processus sont donc à l’œuvre, côte à côte, la réception de nouvelles données et la digestion et assimilation des anciennes » [15]. Selon Chan et al. [16], en accord avec le paradigme de Kuhn4 [19], la MA, en aidant à accroître la précision et la portée d’un paradigme, contribue au progrès de la science dite normale. La MA facilite la prise de conscience par les chercheurs des anomalies d’un domaine et, ce faisant, elle joue un rôle clé dans le déclenchement de crises et de révolutions scientifiques, contribuant ainsi également au progrès de la science (selon le paradigme de Kuhn). Dans le même esprit, Shadish et Lecy5 [20], dans leur article intitulé The meta-analytic big bang examinent l’impact de la MA, puis explorent les raisons pour lesquelles la MA a été élaborée, dans les années 1970, par les chercheurs en sciences sociales, grâce aux travaux concomitants de Glass [11], de Rosenthal [21] et de Schmidt [12]. Ils notent que la MA a impacté toutes les « sciences » (sciences sociales, sciences, droit, médecine…), ainsi que de nombreux domaines tels que la modélisation statistique (modèles multiniveaux…), les statistiques médicales, l’évaluation des programmes. Aujourd’hui les principaux objectifs sont les suivants :
- augmenter la puissance du test statistique, en augmentant la taille de l’échantillon, ou dans le même esprit, d’améliorer la précision de l’estimation de l’effet de taille ;
- lever le doute en cas de résultats apparemment discordants, entre études ou entre revues de la littérature. Dans ce cas, la MA tente d’expliquer la variabilité des résultats disponibles ;
- formuler des hypothèses pouvant aboutir à la réalisation de nouvelles études.
Deux grands types de méta-analyse
La première est la MA sur données individuelles. La seconde est la MA sur données agrégées (résumées), i.e. généralement extraites de publications. La MA sur données individuelles demeure la méthode de référence. Elle permet une vérification et une analyse approfondie des données. Elle est néanmoins plus chronophage que la MA de données agrégées.
Les quatre étapes d’une méta-analyse
Ces étapes doivent être suivies par tout protocole de MA :
- identification des études à inclure ;
- recueil et vérification des données ;
- analyse statistique principale et représentation graphique ;
- exploration et analyse de l’hétérogénéité.
Identification des études à inclure
La stratégie de la recherche de la littérature répondant aux questions doit être systématique [22] : les publications indexées dans les bases de données bibliographiques telles que Pubmed [23], ScienceDirect [24], Cochrane Library [25], Istex, via Inist-CNRS [26], etc., mais aussi les bases de données d’essais cliniques telles que clinicaltrials.gov [27] ou EU ClinicalTrials Register [28] et enfin la littérature grise (rapports d’études ou de recherches, actes de congrès, thèses, brevets… [29,30,31]). Cette dernière est disponible dans des bases telles que OpenGrey [32]6.
Recueil et vérification des données
Une étape importante de la MA est de vérifier la qualité de chaque étude et, le cas échéant, de décider sur des critères objectifs son inclusion ou non dans la MA. Des grilles d’analyse des biais des études sont disponibles et utiles : RoB (Risk of bias) pour les études randomisées [34]7 et Robins pour les études d’observation [35]. Il existe aussi des grilles spécifiques au type d’étude, par exemple Quadas-2 pour la MA d’études diagnostiques [36].
Analyse statistique principale et représentation graphique
Estimation de la taille de l’effet, article par article
L’estimation de la taille de l’effet8, article par article, prend en compte la nature du critère de jugement. Si le critère de jugement est binaire, on pourra estimer un OR, un risque relatif, une différence du risque relatif. Si le critère de jugement est la survie9, on pourra estimer des hazard ratio. Pour les critères de jugement quantitatif (moyenne, médiane, coefficients de corrélation), on pourra les standardiser : moyenne standardisée [6] ; « z-score » pour les coefficients de corrélation.
En ce qui concerne la moyenne standardisée10, le d de Cohen est souvent utilisé [38]. Il conduit à des biais (surestimation de l’effet) en cas de petits échantillons. L’alternative, non biaisée, au d de Cohen est le g de Hedges [39]. La formule de Hedges et Olkin [40], permet de passer de d à g11. Notons que g est le standard utilisé dans le logiciel RevMan de la Cochrane Library [41].
Notons qu’il est possible de convertir un effet en un autre (dans un sens donné…). On peut ainsi convertir un log (OR) (logarithme de l’odds ratio) en d (différence standardisée) et un coefficient de corrélation r, en d. Les différentes formules de conversion sont disponibles dans l’ouvrage de Borenstein et al. (chapitre VII) [6]. Les détails statistiques relatifs concernant la taille de l’effet figurent dans les ouvrages de Ellis [42] et de Grissom et Kim [43].
Estimation de la taille de l’effet global
La taille de l’effet global est estimée via une pondération des effets individuels (i.e. effet estimé par chaque article) par leur précision (inverse de la variance). Deux types de modèles statistiques peuvent être utilisés pour réaliser cette estimation : les modèles à effet fixe et les modèles à effet aléatoire [6,44]. Dans un modèle à effet fixe, on considère que chaque essai i représente une estimation d’un unique « vrai » effet du traitement12.![]()
L’estimation de l’effet commun peut être alors obtenue en utilisant la moyenne des estimations de chaque essai, pondérée par l’inverse de leur variance. Cette pondération est nécessaire du fait que les différentes estimations de i ne sont pas égales en termes de précision ou de variance. L’effet du traitement commun s’écrit alors :
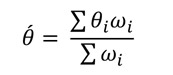
Si l’hétérogénéité est « importante » ou, pour certains, si le test hétérogénéité est statistiquement significatif, il faut alors utiliser un modèle à effet aléatoire. Le modèle à effet aléatoire permet aux effets du traitement de varier, en faisant l’hypothèse que chaque essai représente une estimation d’un réel effet du traitement, lui-même étant une variable aléatoire normalement distribuée autour d’un effet global constant de moyenne et de variance. Ce modèle permet de décomposer la variance totale en une variabilité inter- essai et une variabilité intra-essai. En pratique, la recherche d’hétérogénéité statistique doit être systématique. En l’absence d’hétérogénéité, les modèles à effets fixes et aléatoires conduisent au même résultat.
Modèle à effets fixes ou aléatoires ?
Hunter et Schmidt [45] ont montré que les modèles à effets fixes entraînaient une erreur de type I13 importante, par rapport aux modèles à effets aléatoires. De plus, ils conduisent à des intervalles de confiance de l’effet global qui sont biaisés (étant plus étroits que leur valeur nominale). Ils recommandent de n’utiliser que les modèles à effets aléatoires en routine. Cela ne signifie pas que ces modèles sont la panacée ! Leurs limites ont été récemment (2019) rappelées et résumées par Serghiou et Goodman [47]. Premièrement, ces modèles n’expliquent pas l’hétérogénéité ! Il est recommandé de réduire l’hétérogénéité par des analyses en sous-groupe ou des méta-régressions. Deuxièmement, il existe de nombreuses méthodes pour calculer les estimations des effets. La méthode de DerSimonian-Laird [44] est la plus souvent utilisée14. Elle conduit à des intervalles de confiance trop étroits et des valeurs de p trop petits lorsqu’il y a peu d’études (i.e., inférieures à 10-15) incluses dans la MA et que l’hétérogénéité est importante. Troisièmement, les études de petite taille influencent plus fortement les estimations, qu’en cas d’utilisation des modèles à effets fixes. Le modèle de Doi et Barendregt (inverse variance heterogeneity model ou IVhet model) est une alternative aux modèles à effets aléatoires [49]. Sa mise en œuvre dans les publications est pour l’instant très limitée15.
Représentation graphique des effets individuels et de l’effet global
Elle est réalisée à l’aide du forest plot (graphique en forêt). L’effet du traitement dans chaque essai et l’effet global du traitement sont positionnés sur le même graphique (Figure 1). Nous présentons l’exemple, mis à jour, de la relation entre type alimentation (faible inoculum bactérien ou non) et survenue d’infection chez les patients neutropéniques6 selon deux types d’étude : trois études randomisées (groupe 0) vs cinq études d’observation (groupe 1).
L’OR de chaque essai (carré), est représenté avec son intervalle de confiance à 95% (ligne horizontale). L’OR global (losange et ligne verticale en pointillé) et son intervalle de confiance à 95% (extrémité du losange) sont également représentés. D’autres informations figurent sur le graphique, tels que le I2 qui quantifie l’hétérogénéité, les effectifs de chaque groupe (intervention vs control) et le poids de chaque étude dans la MA. Une pondération utilisée en MA est celle de l’inverse de la variance [50]. On peut noter que pour le sous-groupe des études d’observation, l’étude de Trifilio [51] a un poids de 90,99%.
Les « moustaches » de part de d’autre du losange représentent l’intervalle de confiance de la distribution prédictive approximative d’un futur essai réalisé dans un contexte similaire à celui de la MA16 [52,53]. On note qu’ici, cet intervalle est très large pour les études d’observation, allant de 0,20 à 9,48 (vs 0,60 à 2,69 pour les études randomisées). Le trait vertical passant par 1 correspond à l’égalité entre les deux interventions. Un OR de part ou d’autre de cette ligne est en faveur ou en défaveur de l’intervention (ici, il semble être en faveur d’une alimentation à faible inoculum bactérien). La MA est réalisée en utilisant un modèle à effet aléatoire avec une estimation de tau² (variance de la taille de l’effet) via la méthode de Hartung-Knapp-Sidik-Jonkman [54] (qui est plus adaptée aux MA incluant peu d’études que la méthode classique de DerSimonian et Laird). Pour les études randomisées, l’OR global est de 1,39, avec un intervalle de confiance à 95% allant de 0,72 à 2,66. Pour les études d’observation, l’OR global est de 1,26, avec un intervalle de confiance à 95% allant de 0,66 à 2,44. Donc quel que soit le type d’étude, randomisé ou non, l’alimentation à faible inoculum bactérien n’a pas montré son efficacité dans la prévention des infections chez les patients neutropéniques.
Un point important est qu’ici, uniquement par simplification, nous avons traité les études d’observation comme si elles étaient du même type, ce qui n’est pas le cas. Une des études est une pseudo cohorte rétrospective [51] ; une autre est de type « avant-après » [55] ; une autre est une étude pilote, prospective [56]. Il est recommandé de réaliser l’analyse pour chacun des sous-groupes d’étude d’observation [57].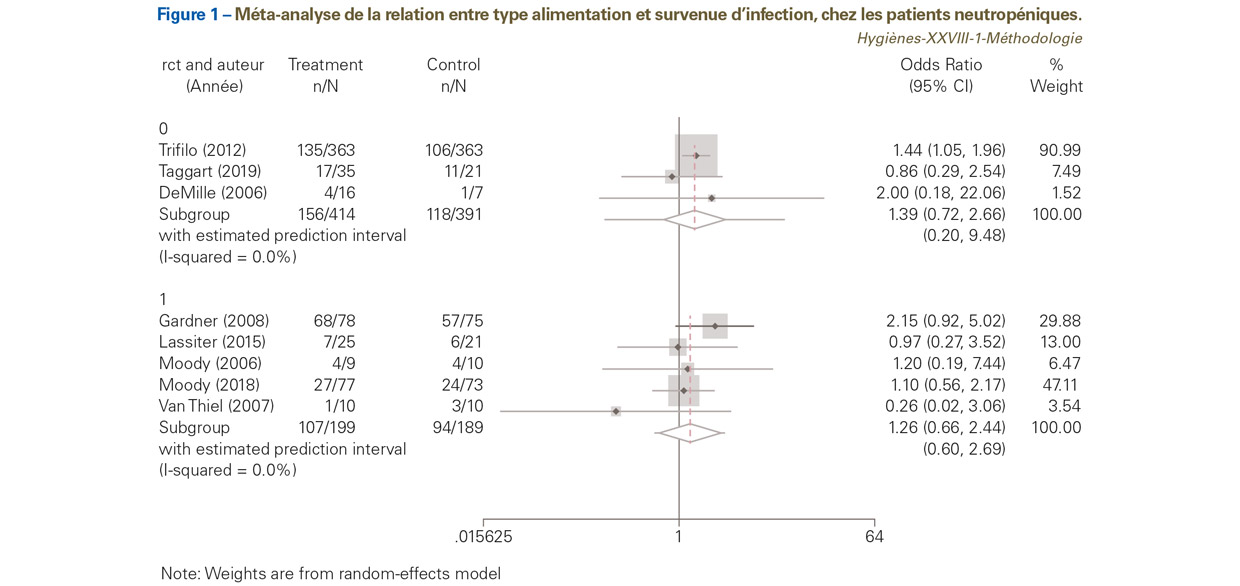
Exploration et analyse de l’hétérogénéité
La recherche d’une hétérogénéité entre les études incluses dans une MA est un point important. En effet, le résultat global obtenu ne peut s’interpréter qu’en l’absence d’hétérogénéité entre les différentes études. Il existe une hétérogénéité lorsque la variation des résultats des essais dépasse la simple fluctuation d’échantillonnage. L’hétérogénéité peut être clinique, avec une différence relative, à la définition de la maladie ; aux critères d’inclusion des patients ; aux méthodes diagnostiques ; à la durée de suivi ; aux doses médicamenteuses ; aux critères de jugement (par exemple, colonisation vs infection), etc. L’hétérogénéité peut être statistique, avec une discordance des résultats des différentes études. Elle peut être liée à un biais de publication, à une méthodologie inappropriée…
L’hétérogénéité statistique peut être décelée graphiquement, via le forest plot, avec des intervalles de confiance de l’effet observé dans les différentes études qui ne se chevauchent pas suffisamment. L’hétérogénéité statistique peut être formellement testée, par exemple via le Q de Cochran ou le I² de Higgins [50,51]. Ce dernier estime la non-concordance (inconsistency) entre les études. Il prend en compte le test Q de Cochran et le nombre d’études incluses dans la MA. Schématiquement, il représente la proportion de variation de l’effet traitement entre les études incluses dans la MA. Des seuils ont été proposés : I²<0,25 = hétérogénéité faible ; I² compris entre 0,25 et 0,5 = hétérogénéité modérée ; I²>0,5 = hétérogénéité importante. Ces tests d’hétérogénéité étant peu puissants, il faut s’assurer, même dans le cas de résultats non significatifs, qu’aucun des essais ne présente de résultats extrêmes. Dans le cas de résultats extrêmes, une analyse de sensibilité peut permettre de conforter le résultat observé.
Que faire en cas d’hétérogénéité ? La démarche classique est d’utiliser un modèle à effet aléatoire (par exemple, utilisant la méthode de DerSimonian et Laird). En l’absence d’hétérogénéité, on pourra utiliser un modèle à effet fixe (modèle de Mantel et Haenszel ou de Peto par exemple) plus robuste pour la mesure d’événements rares. En présence d’hétérogénéité, il faut essayer de l’expliquer. Les sources d’hétérogénéité sont identifiées par l’analyse qualitative des études incluses. Les approches peuvent graphiques, statistiques (via des tests) ou mixtes. La recherche d’études pouvant entraîner une hétérogénéité est possible en inspectant le graphique des OR (ou autre mesure d’effet) [58]. Baujat et al. [59] ont ainsi proposé une méthode graphique qui permet de visualiser facilement les essais les plus hétérogènes et les plus influents de la MA sur un graphique en deux dimensions (Figure 2). On représente : (i) en abscisse, la contribution de chaque étude à la statistique globale d’hétérogénéité ; (ii) en ordonnée, la différence standardisée de l’effet global du traitement, avec et sans chaque étude (cette quantité décrit l’influence de chaque étude sur l’effet global du traitement). Les études qui s’éloignent de la masse des observations sont suspectes d’être source hétérogénéité.
Dans notre exemple, les études numérotées « 1 » et « 5 » sont suspectes d’être source d’hétérogénéité.
L’hétérogénéité peut aussi être explorée à l’aide d’assez nombreuses autres méthodes qui sont présentées par l’Annexe I – Autres méthodes d’étude de l’hétérogénéité17. Il s’agit entre autres du graphique radial de Galbraith [60], du graphique de Labbe [61] des analyses en sous-groupes avec méta-régression prenant en compte par exemple l’année de publication, du funnel plot qui suggère un biais de publication, des tests d’Enger et de Begg, de la méthode trim-and-fill, etc.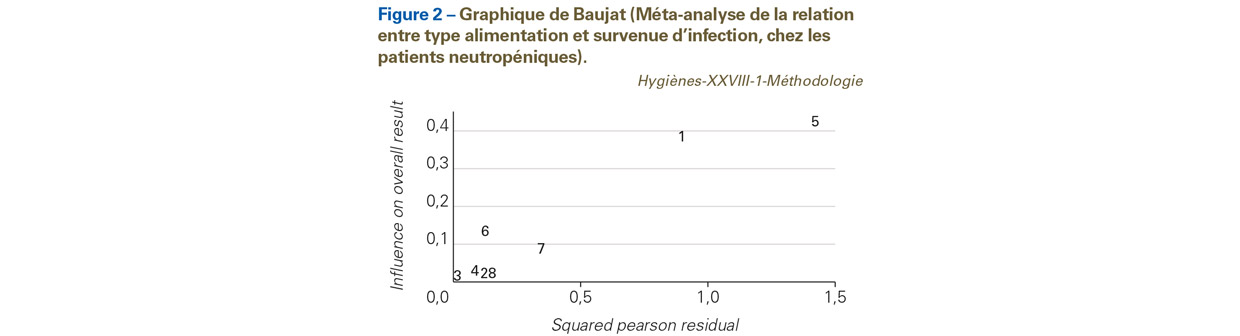
Analyse de sensibilité : méta-analyse leave-one-out
Cette procédure peut être vue comme une analyse de sensibilité18. L’objectif est de montrer comment chaque étude affecte l’estimation de l’effet global procuré par la MA. La MA leave-one-out consiste à effectuer une MA en omettant une étude. Le processus est répété jusqu’à ce que toutes les études soient omises. Il est possible d’omettre plus d’une étude à la fois, mais les calculs deviennent volumineux, en raison du nombre élevé de combinaisons possibles19.
Les résultats concernant notre exemple sont dans la Figure 3. On note pour les études d’observation, que l’omission de l’étude de Trifilio [51] dans la MA conduit à une estimation très imprécise de la taille de l’effet, avec un OR de 0,99, mais surtout un intervalle de confiance allant de 0,002 à 585,820. Pour les études randomisées, l’omission d’une des études, quelles qu’elles soient, ne semble pas beaucoup influencer l’estimation de l’effet global.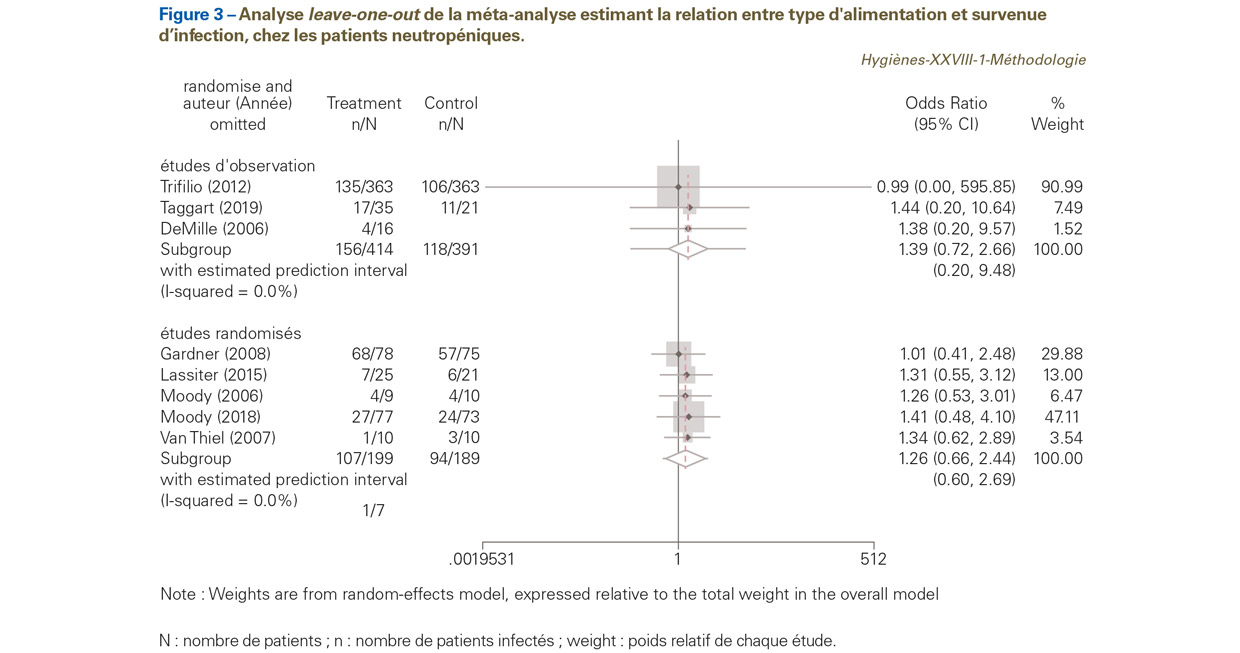
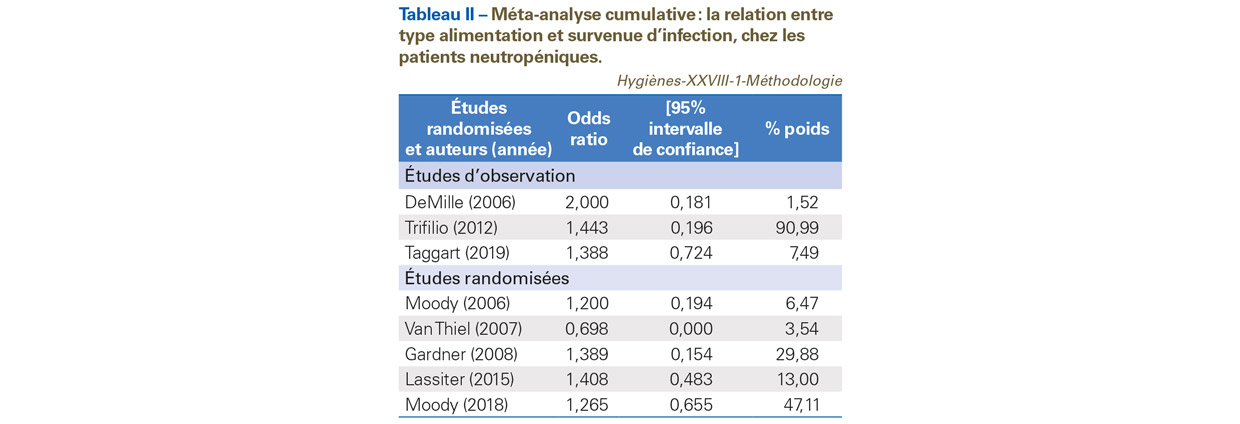
Méta-analyse cumulative
La MA cumulative consiste à effectuer une MA en introduisant les études les unes après les autres, afin de suivre l’évolution de l’effet global. Le processus est répété jusqu’à ce que toutes les études soient incluses. L’ordre d’introduction le plus fréquent est chronologique (par date de publication), afin de détecter une tendance temporelle, mais d’autres ordres sont possibles tels que la précision (inverse de la variance) [63]. Cette dernière variante de MA cumulative permet aussi de détecter les biais de publication [63,64]. La MA cumulative n’est pas une réactualisation de la MA. La réactualisation d’une MA consiste à estimer un nouvel effet global, chaque fois qu’une nouvelle étude est disponible. Des analyses statistiques appropriées telles que la MA séquentielle, doivent être utilisés.
Les résultats de notre exemple figurent dans le Tableau II. On note, malgré l’imprécision des intervalles de confiance liée au modèle utilisé, que les estimations sont similaires pour les études randomisées et pour les études d’observation, à la dernière étude publiée. Il n’y a pas assez d’études dans la MA pour voir se dégager une éventuelle tendance temporelle.
Nous avons illustré cette première partie à l’aide d’un exemple de MA incluant peu d’études, ce qui reflète la réalité. En effet, selon l’étude Davey et al. [65], conduite sur la base de données Cochrane, le nombre médian d’études par méta-analyse n’est que de trois sur un total de 22 453 méta-analyses concernant la santé.
La seconde partie de cette mise au point méthodologique sera consacrée aux aspects particuliers de la méta-analyse. On abordera entre autres :
- l’agrégation ou non des données : MA sur données individuelles [66]. C’est la référence. Elle est plus chronophage et un peu plus compliquée à mettre en œuvre que la MA sur données agrégées ;
- la MA en réseau [67], est utilisée lorsque les interventions n’ont pas été comparées, mais ont été étudiées par rapport à un comparateur commun ;
- la MA bayésienne [68] qui s’applique à tous les aspects statistiques de la MA.
Notes :
1- Dans le présent texte, essai est assimilé à étude. L’essai peut être comparatif (randomisé ou non) ou non comparatif (par exemple une étude de prévalence).
2- Le paradoxe de Simpson (ou paradoxe de Yule-Simpson) a été initialement décrit par Karl Pearson en 1899. En 1903, Undy Yule le redécouvre. En 1951 Edward Simpson publie un article détaillé sur le sujet [1]. Ce paradoxe est lié au fait qu’une association entre deux variables peut disparaître ou même s’inverser suivant que l’on considère les données dans leur ensemble, ou bien segmentées par groupes. Ce paradoxe se produit en présence de facteur de confusion [2]. Dans le cas des essais randomisés, lorsqu’un ou plusieurs des essais inclus dans la MA n’utilisent pas un schéma de randomisation de type « un-pour-un » (i.e. à chaque individu randomisé dans le groupe « intervention » correspond un individu randomisé dans le groupe témoin), la simple mise en commun des données des essais (« moyenne simple ») peut conduire au paradoxe de Simpson. Lorsqu’il y a de grandes disparités de taille d’échantillon parmi les essais, l’impact dudit paradoxe peut être assez important. Voir également : Goltz et al. pour le paradoxe de Simpson dans la recherche scientifique [3] et Delaye JP pour les paradoxes mathématiques, dont celui de Simpson [4] (p. 115-118, pour le paradoxe de Simpson).
3- Karl Pearson est aussi l’auteur d’un des tests statistiques les plus utilisés, le test du Chi-2 [8].
4- Dans son ouvrage La structure des révolutions scientifiques, publié en 1962 [17], Thomas S. Kuhn insiste sur les bouleversements de la pensée scientifique liés aux travaux de Copernic, Newton, Einstein, etc. Kuhn analyse ces moments de crise que traverse la science. Il mentionne également les conditions requises pour l’apparition d’une telle crise. Pour Kuhn, il y a révolution scientifique lorsqu’une théorie scientifique consacrée par le temps est rejetée au profit d’une nouvelle théorie. L’ouvrage de Kuhn a été traduit en français, sous le titre La structure des révolutions scientifiques [18].
5- Ces auteurs analysent enfin pourquoi la MA a vu le jour dans les années 1970 dans le domaine des sciences sociales grâce aux travaux de Gene Glass, Robert Rosenthal et Frank Schmidt, qui ont chacun élaboré des théories similaires de MA à peu près au même moment. L’article se termine en expliquant comment la théorie de la « configuration aléatoire » (« chance-configuration ») de Simonton et l’épistémologie évolutionniste de Campbell peuvent expliquer pourquoi la MA a eu lieu avec ces chercheurs et non en sciences médicales.
6- Voir la note méthodologique concernant la méthode Grade (parue dans Hygienes en 2018 [33]).
7- Une mise à jour sera bientôt disponible : Sterne JAC et al. RoB 2: a revised tool for assessing risk of bias in randomised trials. BMJ (in press) [34].
8- Il arrive que cet effet figure dans les articles. Parfois, la taille de l’effet n’est pas disponible dans l’article et il faut l’estimer, ainsi que son écart-type, a posteriori.
9- D’une manière générale, le terme survie est relatif à un évènement binaire (décès, pathologie…) survenant au cours du temps, plus précisément le temps au bout duquel l’évènement se produit (time to event). Voir l’ouvrage de Hill et al. [37] pour plus de détails.
10- Moyenne standardisée = (moyenne du « groupe 1 » – moyenne du « groupe 2 ») / écart-type commun des deux « groupes ». Les groupes peuvent respectivement être un groupe « témoin » et un groupe « traitement ».
11- Formule de Hedges et Olkin : 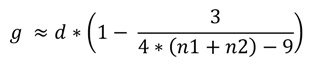
12- Dans le présent texte, un traitement est assimilé à une intervention, pharmacologique ou non (par exemple un dispositif médical tel que le masque…).
13- L’erreur de type I correspond au « fameux » p ou α. L’erreur de type I survient, dans un test d’hypothèse, statistique, lorsque l’hypothèse nulle, qui est en réalité vraie, est rejetée par erreur. L’erreur de type II survient lorsque l’hypothèse nulle est acceptée par erreur. Selon JF Bach, « Mieux vaut se tromper quelques fois que de ne pas entreprendre une démarche scientifique originale par peur de commettre une erreur » [46].
14- DerSimonian et Laird ont publié, près de 20 ans après leur article princeps, une mise à jour de leur méthode, avec entre autres, l’utilisation d’un estimateur robuste de variance [48].
15- Moins de trente articles mentionnant cette méthode dans Pubmed, et 122 citations dans Google Scholar, au 22 juillet 2019 ; vs 25 762 citations dans Google Scholar pour l’article de DerSimonian et Laird [44]. Il faut bien entendu pondérer par l’ancienneté de la publication (et non pas par l’inverse de la variance…).
16- Celui-ci n’est pas estimable s’il y a moins de trois études.
17- L’annexe est disponible sur le site internet de la revue pour les abonnés numériques (www.hygienes.net) ou sur simple demande à l’auteur correspondant.
18- Sur le plan statistique, la méthode leave-one-out est une technique de re-échantillonnage et un cas particulier de validation croisée.
19- Il s’agit d’un problème élémentaire d’analyse combinatoire (configurations possibles d’une collection d’objets ou d’un ensemble de situations…) : combien de paires, de triplets, de quadruplets, etc., avec k études incluses dans la MA. Pour plus de détails sur l’analyse combinatoire, voir par exemple l’ouvrage de Martin [62].
20- La variance tau² a été difficile à estimer avec le modèle REML et Hartung-Knapp-Sidik-Jonkman.